What is overfitting?
Overfitting is a concept in machine learning and statistics that refers to a model that is excessively complex, such as having too many parameters relative to the number of observations. An overfitted model is one that is tailored too closely to the training data and captures the noise along with the underlying pattern in the data.
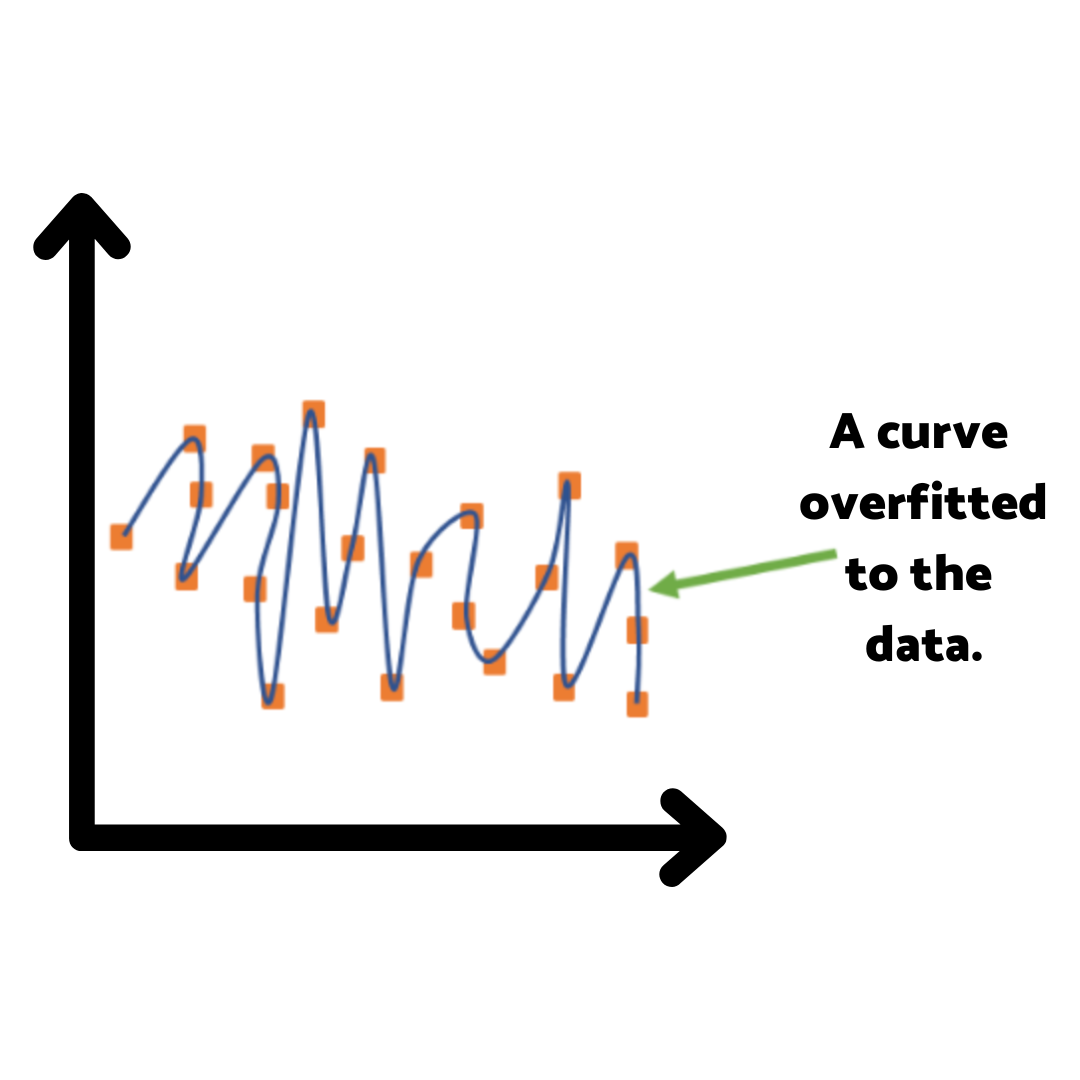
An example: the overfitted studying strategy
Imagine for a moment that you’re a student cramming for an exam. You’re desperate, fueled by vending machine coffee and the terror of impending failure.
So you start to memorize all the previous tests—every last question, multiple choice array, and answers. You start to become confident that you can predict the questions that will be on the next exam.
But then the test comes and instead of asking you to regurgitate specifics from the last tests, it asks you to think. To apply what you’ve supposedly learned to new situations. You’re stuck, flailing in the deep waters of understanding. All those late nights, all the caffeine crashes, all for naught.
Well, that’s overfitting. It’s like a computer program that’s been crammed so full of specifics and minute details from its training data that it’s more of a trivia master than an intelligent machine.
Here’s a nice little comic to illustrate this error in a different arena.
Sure, it’s great when you throw the exact same stuff back at it, but as soon as it has to handle anything new, anything different—it chokes.

The moral of this tale?
Any time we look to the past to understand the future we are in danger of overfitting our data. We think just because we have a model for predicting exactly what happened in the past, we can predict the future.
So when we look at the past we should keep in mind that we only see one single outcome. In reality, there was always a large array of possible outcomes at each step along the way.